this is exciting and ambitious, love to see it, rooting for you!
2
Building Tooling to Map how Ideas Spread
ProposalGrant
Closes May 12th, 2025$2,580raised
$1,000minimum funding
$100,000funding goal
Offer to donate
40 daysleft to contribute
This is an offer to donate this amount to the project on the condition that it eventually becomes active. Otherwise, your funds will remain in your Manifund account.
The Nooscope
A telescope (and microscope) into the noosphere (the realm of ideas between people).
It’s a tool to see how ideas spread—where do they come from, who do they stick with, how do they change?
I like to imagine ideologies competing, merging, forking like microbes.
If we can trace where a given idea comes from, we can detect if it emerged organically or if it was intentionally and artificially promoted.
E.g. Can we tell whether Barbenheimer was an organic phenomenon or marketing?
Motivation
The internet is like a jungle - full of opportunity, but also threats.
Humans are vulnerable to harmful narratives, which are especially easy to spread intentionally online. Misinformation is a well known global risk costing $10Bs if not $100Bs per year and getting worse as AI improves.
We can build tools that give us “jungle eyes”, spotting psyops and harmful memes in our communities. By becoming aware of them earlier, we can mitigate risks from harmful memes like anorexia or unhealthy attachment to “AI partners” before they scale.
Just like in cybersecurity, we can publicly study & document security vulnerabilities. Transparency helps defensive coordination, and no one else is doing this openly.
Momentum
Crowdsourced Data
To research memetics, we needed data, so we started a movement to bootstrap our own with the Twitter Community Archive, a crowdsourced database of Twitter archives.
The archive is an open database and API with 16M tweets from the volunteered archives of ~250 accounts. The cold start only worked because we’re trusted community members and campaigned to get people to upload.
Community Archive front page
It can scale:
Serve more communities. The software is open-source, so anyone can start a database for their community.
Real time data firehose via our browser extension, avoiding the laborious upload process.
Include Bluesky data. We could easily do this on bluesky because it’s open but twitter still has the most juice.
As more tools appear, more people upload and the data grows, and as the data grows, more devs build tools.
Open-source tools and an active dev community
The quality of the data is attested to by an active discord of 180 builders, 40 of whom were present at our NYC hackathon, with 16 submissions of tools and research.
We’ve already built relevant 1st-party tools. A few examples:
📈The Keyword Trends App lets you visualize the occurrence of terms
🐦Birdseye lets you explore topics and trends in your posts;
🕸️ Personal Semantic Search - search individual archives semantically
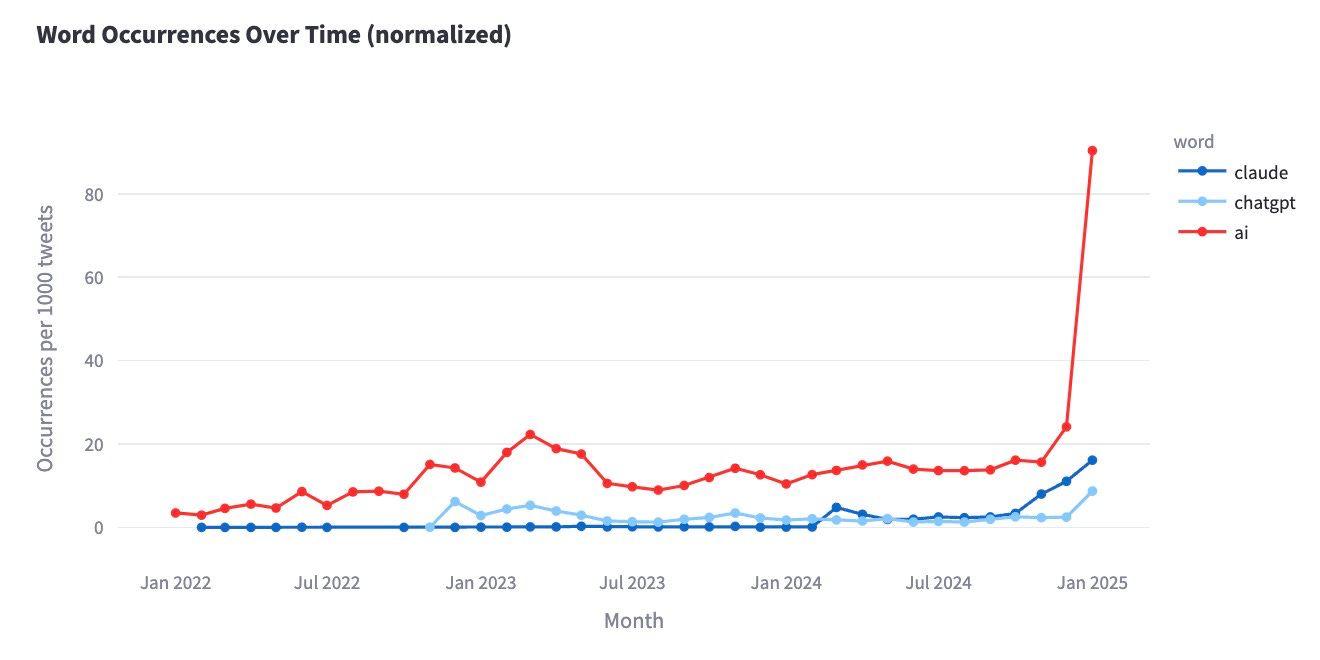
Keyword trends, the simplest memetics tool.

Tweet clustering from Birdseye, mapping long-term topics for each account.
Roadmap
To build the nooscope we need social media data, data science, and contemporary AI.
Without getting too technical,
we’d want to get our essential data-science primitives running on tweets and accounts - that’s embeddings, clustering, network visualization, etc. [1] We want all of these running very efficiently in the browser, leveraging WebAssembly.
Then we learn how to combine these primitives in concrete experiments to track known events and stories.
Then iterate towards an integrated tool to explore idea diffusion in the user-interaction networks present in our 16M tweet dataset.
By the end, we want to help at least 2 other communities to set up their own separate archives (proving that scaling pathway), establish partners to integrate with bluesky, and prove real utility by detecting 5 real-time psyops.
To house the nooscope and the community archive, we’ll establish the open memetics institute as an umbrella organization and attractor for like-minded researchers and devs. We’ve been building the only open memetics community on earth already in the community archive discord.
Footnote:
[1] The data science primitives we want running on tweets and accounts:
Embeddings,
Semantic search,
Clustering,
Network visualization,
Network diffusion,
Named entity search,
Event detection in time series.
Team
I’m @exgenesis on twitter. I’ve worked in AI safety and have worked for years on improving online sensemaking:
2024: Launched Community Archive - a crowdsourced db and open API with 16M tweets from 250 high-quality accounts.
2023: I joined hive.one, an index of twitter communities, to work on twitter data analysis, including community detection.
2021: I built Threadhelper, (Emergent Ventures 7th cohort) a browser extension that turns twitter into a collaborative thinking tool. (1000s of users)
Team
Francisco Carvalho, @exgenesis - CEO, MLE, research
@iaimforgoat - SWE, database maintenance
Omar Shehatha, @DefenderOfBasic - Community manager, research
Informal Advisors
Ivan Vendrov (leading collective intelligence at Midjourney)
Brent Baum (CEO of Refract)
Rich Bartlett (CEO of Microsolidarity)
REDACTED advisor (will show after permission)
Budget
Our goal is to raise $100k. Vitalik Buterin DMed me pledging to 1:1 match $25k of donations.
$60k: Living expenses for @exgenesis for a year, full-time.
$20k: Hire @iaimforgoat, our best contributor, part-time for a year.
$10k: Compute, travel expenses, and other operating costs.
$10k: Fiscal sponsorship and ops.
$100k is really our minimum, and a stretch goal of $250k would enable us to hire Goat and another contributor full time, and afford us more runway and travel budget for conferences.
We expect our research to lead to public goods as well as for-profit opportunities, e.g. memetics-informed matchmaking.
What are the most likely causes and outcomes if this project fails?
If X pursues us legally for not adhering strictly to X terms of service, that may trigger an interesting public discussion, and I have the sense many of the people in the archive are people whose opinions Elon cares about, That would causes us to redirect our efforts to bluesky data, which is much easier to work with.
How much money have you raised in the last 12 months, and from where?
$3649 from our community through opencollective.